

In einem Video erfahren Sie mehr über die Verwendung von Sondertagen zur Verbesserung der Vorhersagegenauigkeit.
Wenn Sie den Schritt Prognosedaten überprüfen, sehen Sie sowohl das prognostizierte Volumen als auch die AHT für alle ausgewählten Fertigkeiten. Die Daten könnten ungenau erscheinen, während Sie normale Werte erwarten:
-
Sie sehen in einigen Bereichen, wo die AHT oder das Volumen ungewöhnlich niedrig oder bei 0,00 ist.
-
Sie sehen Volumenspitzen am Dienstag und Mittwoch, aber die historischen Daten zeigen Spitzenwerte am Montag und rückläufige Trends bis Freitag.
In diesen Fällen sollten Sie Änderungen an den historischen Daten vornehmen.
Suchen Sie im Schritt Historische Daten nach Tagen, die nicht ganz dem Standard entsprechen. Zum Beispiel könnte das Volumen an einem bestimmten Tag aufgrund einer Produktwerbung zu hoch sein. Dies ist kein normaler Tag. Aus diesem Grund zeigen die Prognosedaten ein ungenaues Volumen oder eine ungenaue AHT für einige Fertigkeiten.
Um die Genauigkeit der prognostizierten Mengen und AHT zu verbessern, definieren Sie diese Tage als Sondertage. Wählen Sie in den Einstellungen für den Sondertag die Option Diesen Tag von zukünftigen Prognosen ausschließen. Diese Tage werden im Schritt Prognosedaten nicht berücksichtigt.
Wenn das prognostizierte Interaktionsvolumen für einen ganzen Tag 0 ist, können Sie das Volumen nicht bearbeiten.
Sie können prüfen, ob das Volumen für den ganzen Tag 0 ist, indem Sie die Daten nach Tag (1D) anzeigen. In der Tagansicht sehen Sie Daten für jedes Intervall während des Tages.
Wenn das Volumen für alle Intervalle 0 ist, ist dies der Grund, warum Sie die Daten nicht bearbeiten können.
Um das Volumen bearbeiten zu können, ändern Sie mindestens ein Intervall.
Zum Beispiel ist das prognostizierte Interaktionsvolumen am 25. Januar 0. Sie betrachten zurzeit die Monatsansicht (1M). In diesem Fall können Sie keine Bearbeitung oder Bulk-Bearbeitung durchführen.
So bearbeiten Sie das Volumen für den 25.:
-
Gehen Sie zur Tagesansicht (1D).
-
Bearbeiten Sie mindestens ein Intervall. Sagen wir 25. Jan. 8:00 Uhr. Statt 0 schreiben Sie 1 oder den gewünschten Wert für dieses Intervall.
-
Um Änderungen für den gesamten Tag vorzunehmen, gehen Sie zurück zur Monatsansicht (1M) und führen Sie die Bearbeitung durch.
Wenn Sie einen Prognoseauftrag erstellen, werden die Prognosedaten in zwei Phasen berechnet. In der ersten Phase werden die Daten in "Prognosedaten" (Schritt 3 der Prognose) auf Basis der erforderlichen Skills generiert. In der zweiten Phase können die Prognosedaten verbessert werden, indem die Arbeitsbelastung auf mehrere Planungseinheiten verteilt wird. Nach der Definition der Personalparameter (Schritt 4) werden die Daten neu generiert. Jetzt werden bei der Berechnung auch die Planungseinheiten berücksichtigt, die die Interaktionen verarbeiten können. So wird sichergestellt, dass die Prognosedaten so genau wie möglich sind. Die Prognosedaten werden in "Personal" aktualisiert (Schritt 5).
Wenn Sie einen Zeitplan auf Basis eines Prognoseauftrags generieren, basieren die Prognosedaten auf den Daten in Schritt 5. Die endgültigen Prognosedaten werden auch in den Spalten "Prognose" im Intraday-Manager angezeigt.
Im Rahmen des Prognoseprozesses (Schritt 3) wird eine Rohprognose erstellt, die sich ausschließlich auf das Volumen und die durchschnittliche Bearbeitungszeit (AHT) pro Qualifikation konzentriert, ohne die Agenten zu berücksichtigen. Von (Schritt 3) bis (Schritt 5) findet ein Simulationsprozess statt, bei dem die Agentenanforderungen an jede Planungseinheit verteilt werden, die die prognostizierten Fähigkeiten verarbeitet. Diese Anforderungen werden dann wieder in Volumen pro Fähigkeit pro Planungseinheit umgerechnet.
In Schritt 5 können wir, wie im Screenshot dargestellt, das Volumen und die durchschnittliche Bearbeitungszeit (AHT) für das Intervall von 8:00 Uhr bis 8:15 Uhrbeobachten. Dies gibt die erwartete Anzahl der Kontakte an, die pro Planungseinheit und Qualifikation als Ergebnis der Simulation bearbeitet werden können.
Nehmen wir an, Sie haben ACD im April 2021 aktiviert. Von da an werden historische Daten gesammelt. Anschließend haben Sie WFM im November 2022 aktiviert. Da Sie historische Daten seit über einem Jahr sammeln, sollten Sie in der Lage sein, diese bei der Erzeugung einer Prognose automatisch zu verwenden.
Laut Prognoseauftrag sind jedoch keine historischen Daten vorhanden (in Schritt 2). Wenden Sie sich an den Support, um dieses Problem zu beheben. Dieser wird die historischen Daten, die Sie gesammelt haben, in WFM importieren.
Das System funktioniert wie vorgesehen. Die Auto-Select-Funktion wählt basierend auf früheren Daten automatisch das beste Prognosemodell aus. In diesem Fall wählte das System das Modell aus, das für die ihm vorliegenden Daten am genauesten erschien. Auch wenn es donnerstags zu einem Spitzenwert kam, ist dies Teil der beabsichtigten Funktion des Systems: Es wählte die Option aus, die auf Grundlage früherer Ergebnisse als die beste erschien.
Der Unterschied in den Ergebnissen ergibt sich aus der Art und Weise, wie die beiden Modelle mit den Daten umgehen:
-
Das Auto-Select-Modell wählte eine Prognosemethode aus, die für die vergangenen Daten am besten funktionierte, erkannte jedoch ein wöchentliches Muster (wie den Spitzenwert am Donnerstag) und übertrug es in die Zukunft.
-
Das Modell der exponentiellen Glättung (ES) glättet die Daten, wodurch es weniger empfindlich auf die Spitzen vom Donnerstag reagiert und eine stabilere Prognose ermöglicht.
Beide Modelle liefern unterschiedliche Ergebnisse, da sie für die Verarbeitung der Daten auf unterschiedliche Weise konzipiert sind und jedes Modell je nach Verhalten der Daten seine Stärken hat.
Das Auto-Select-Modell macht genau das, wofür es entwickelt wurde: Es wählt das Modell aus, von dem es auf der Grundlage historischer Daten die genaueste Prognose liefert. In seltenen Fällen wie diesem kann es jedoch vorkommen, dass das Modell ungewöhnliche Muster erkennt, die für die Zukunft nicht mehr gelten, wie etwa den Anstieg am Donnerstag. Der Kunde kann die automatische Auswahlfunktion verwenden, muss in bestimmten Situationen jedoch möglicherweise manuell ein anderes Modell auswählen (z. B. exponentielle Glättung), um eine genauere Prognose zu erhalten.
Da der Kunde über eine erweiterte Lizenz verfügt, hat er die Möglichkeit, das Prognosemodell manuell auszuwählen, wenn er der Meinung ist, dass das automatisch ausgewählte Modell nicht die besten Ergebnisse liefert. Diese Flexibilität ermöglicht es ihnen, das für ihre spezifischen Anforderungen am besten geeignete Modell auszuwählen.
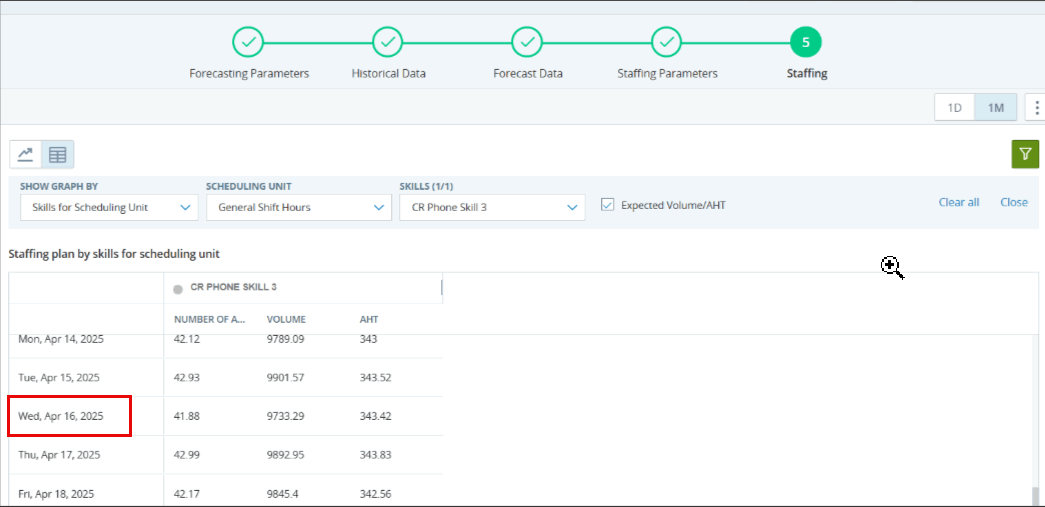
Betrachten wir im Besetzungsbildschirm für die unten stehende Stelle ein Intervall am 15. Januar für die Fähigkeit „Contact Center“, wie im Bild unten hervorgehoben:
Im obigen Beispiel können wir sehen, dass das Volumen 4,71 mit einem AHT von 100,43 für die Fertigkeit Contact Centerbeträgt. Dies bedeutet, dass innerhalb eines 900-Sekunden-Intervalls (15 Minuten) alle Anrufe von einem einzigen Agenten mit einer AHT von 100,43 bearbeitet werden. Wenn wir die genauen Zahlen in unsere Berechnungen einbeziehen, ist der Personalbedarf von 0,53 korrekt, da in der Dispositionseinheit 67 Agenten tätig sind.
Eine Änderung des Servicelevels hat keine Auswirkungen auf die Personalausstattung, da wir über genügend Agenten verfügen, um die Anrufe zu bearbeiten. Wenn wir uns die Contact Center-Konfiguration in der Planungseinheit während der Personalgenerierung ansehen, sehen wir, dass insgesamt 67 Agenten zur Bearbeitung von Anrufen für die ausgewählte Fähigkeit zur Verfügung stehen. Wenn also bei der Generierung des Personalbedarfs genügend Agenten zur Verfügung stehen, um die prognostizierten Interaktionen in jedem Intervall abzuwickeln, wird SLA ASA nicht berücksichtigt.
Wenn jedoch nicht genügend Agenten zur Verfügung stehen, um die prognostizierten Anrufe während eines bestimmten Intervalls zu verwalten, wird die SLA-ASA-Metrik verwendet, um die Anzahl der Agenten zu bestimmen, die zum Erreichen der Service-Level-Ziele erforderlich sind. Dieses Prinzip gilt für alle Intervalle, Fähigkeiten und Planungseinheiten dieser Rolle. Angesichts des geringen Volumens und AHT sowie der ausreichenden Anzahl verfügbarer Agenten bleibt die Personalstärke unverändert. Da genügend Agenten vorhanden sind, um das SLA von 100 % durchgehend zu erfüllen, wird der ASA effektiv mit Null berechnet.
Basierend auf der historischen Datenanforderung überprüfen wir, ob die ACD-Fähigkeit eingehend oder ausgehend ist und ob die WEM-Fähigkeitsrichtung eingehend oder ausgehend ist. Falls sie nicht übereinstimmen, weist eine Meldung auf der Verlaufsseite auf eine Abweichung in der Richtung hin.
Fehlermeldung:
-
Die WEM-Skills-Ausrichtung stimmt nicht mit ACD überein. Richten Sie diese WEM-Fähigkeiten auf ACD aus: Kundensupport OB.
Mögliche Ursachen:
-
Fall 1: Die WEM-Fähigkeit ist eingehend, aber die ihr zugeordnete ACD-Fähigkeit ist ausgehend.
-
Fall 2: Sowohl die WEM- als auch die ACD-Fähigkeiten sind ausgehend, aber die hochgeladenen historischen Daten sind als eingehend markiert.
-
Fall 3: Sowohl die WEM- als auch die ACD-Skills sind eingehend, die hochgeladenen historischen Daten sind jedoch als ausgehend gekennzeichnet, da das ausgehende Flag während des Uploads auf True gesetzt wurde.
-
Fall 4: Die ACD-Fertigkeit wurde gelöscht und neu erstellt. In diesem Fall geht die ursprüngliche Zuordnung zwischen der WEM-Fähigkeit und der ACD-Fähigkeit verloren.
Umgehungslösung:
-
Stellen Sie sicher, dass die historischen Daten entsprechend der ACD-Skill-Konfiguration hochgeladen werden. Wenn die ACD-Fähigkeit als ausgehend definiert ist, setzen Sie das isOutboundFlag während des Uploads auf True. Andernfalls, wenn die ACD-Fähigkeit als eingehend definiert ist, setzen Sie das isOutboundFlag auf False.
-
Wenn eine ACD-Fertigkeit gelöscht und neu erstellt wurde, ordnen Sie die WEM-Fertigkeit der neu erstellten ACD-Fertigkeit neu zu.
-
Wenn eine ACD-Fähigkeit als eingehend zugeordnet ist, die zugehörige WEM-Skill jedoch die Einstellung Zu Kanal zuweisen auf Dialer hat, muss die WEM-Skill gelöscht werden. Erstellen Sie eine neue WEM-Fertigkeit vom Typ „Inbound“ und verknüpfen Sie diese mit der entsprechenden Inbound-ACD-Fertigkeit.
-
Laden Sie historische Daten von WFM > Forecasting > ACD Historische Daten neu und stellen Sie sicher, dass mindestens 13 Wochen an historischen Daten für eine genaue Prognose verfügbar sind.
In CXone Mpower WFM, ist Target ASA (Average Speed of Answer) ein optionaler Parameter, der bei der Personalplanung verwendet wird.
-
Sie können eine Ziel-ASA als Teil Ihrer Personalparameter definieren, dies ist jedoch nicht obligatorisch.
-
Wenn Sie keine Ziel-ASA definieren, wird der Personalplanungsprozess dennoch unter Verwendung anderer Eingaben, wie z. B. des Servicelevel-Ziels, durchgeführt, um Personalempfehlungen zu generieren.
Bei der Personalplanung führt das System eine Simulation durch, die nachbildet, wie Kontakte in einem realen ACD eintreffen, in die Warteschlange gestellt und beantwortet werden. Auf Grundlage dieser Simulation ermittelt das System:
-
Die Anzahl der Agenten, die erforderlich sind, um die definierten Ziele (Servicelevel und/oder ASA) zu erreichen.
-
Die durchschnittliche tatsächliche Wartezeit, die Kunden bei der berechneten Personalstärke erleben würden.
Diese tatsächliche Wartezeit wird zur Prognostizierten ASA, die im Intraday-Modus angezeigt wird.
-
Wenn ein Ziel-ASA definiert ist, spiegelt der prognostizierte ASA das Simulationsergebnis auf Basis dieses Ziels wider.
-
Wenn kein Ziel-ASA definiert ist, wird der prognostizierte ASA dennoch automatisch im Rahmen der servicelevelbasierten Simulation berechnet.
Unabhängig davon, ob ein Ziel-ASA konfiguriert ist, zeigt Intraday immer einen prognostizierten ASA auf Basis der Personalsimulation an.
Wenn mehrere Serviceziele wie Servicelevel, Ziel-ASA und Maximale Belegung für dieselbe WEM-Skill definiert sind, CXone Mpower WFM bewertet alle Ziele während der Personalsimulation gleichzeitig.
-
Das System berechnet die Anzahl der benötigten Agenten, um jedes einzelne Ziel zu erreichen.
-
Anschließend wird derjenige mit dem höchsten Personalbedarf ausgewählt.
Zum Beispiel:
-
Um das Servicelevel-Ziel zu erreichen, werden 20 Agenten benötigt.
-
Target ASA benötigt 22 Agenten
-
Maximale Belegung erfordert 18 Agenten.
-
Endgültiger Personalbedarf = 22 Agenten (das Maximum von drei)
-
Dieser Ansatz gewährleistet, dass die Personalempfehlungen alle definierten Serviceziele erfüllen, nicht nur eines.
Wenn für dieselbe WEM-Skill mehrere Serviceziele definiert werden, besetzt das System immer das Personal entsprechend der restriktivsten (größten) Anforderung, um sicherzustellen, dass alle Ziele erreicht werden.
Es wird generell nicht empfohlen, mehrere Serviceziele für dieselbe WEM-Skill zu definieren. Jedes Ziel hat unterschiedliche Auswirkungen auf den Personalbedarf und kann zu widersprüchlichen Einschränkungen führen. Beispiel:
-
Servicelevel und Ziel-ASA zielen darauf ab, die Wartezeiten für Kunden zu reduzieren.
-
Die Maximale Belegung schränkt den Einsatz von Agenten ein, was mit den Zielen von SL und ASA in Konflikt geraten kann.
Trotzdem bietet CXone Mpower WFM die Flexibilität, solche Szenarien bei Bedarf zu unterstützen. Der Personalbedarf-Rechner wertet mehrere ausgewählte Ziele aus, die entweder im Personalprofil oder direkt im Prognosejob definiert sind, und generiert Personalempfehlungen, die diese gleichzeitig erfüllen.
Es obliegt dem Benutzer, sicherzustellen, dass die ausgewählten Ziele aufeinander abgestimmt sind und sich nicht widersprechen. Die Aktivierung mehrerer Ziele erhöht die Restriktion der Personallösung, was zu Überbesetzung oder nicht realisierbaren Dienstplänen führen kann.
Der Prognosealgorithmus verwendet verschiedene Methoden zur Berechnung der durchschnittlichen durchschnittlichen Heiztemperatur (AHT) basierend auf der Menge der verfügbaren historischen Daten:
Wenn weniger als 2 Jahre an historischen Daten verfügbar sind:
-
Der Algorithmus verwendet einen gleitenden gewichteten Durchschnitt zur Schätzung der AHT.
-
Diese Berechnung wird auf Intervallebene durchgeführt, wobei den jüngsten Datenpunkten innerhalb jedes Zeitintervalls Gewichte zugewiesen werden (z. B. 15-Minuten- oder 30-Minuten-Blöcke).
Falls historische Daten aus mehr als zwei Jahren verfügbar sind:
-
Der Algorithmus wertet mehrere Kandidatenmodelle aus und wählt dasjenige mit dem niedrigsten Mean Absolute Error (MAE) aus.
-
Diese Modellauswahl wird auch auf Intervallebene angewendet, sodass jedes Intervall das am besten passende Modell auf Basis seines historischen AHT-Verhaltens verwenden kann.
Zusammenfassung:
-
< 2 Jahre Daten: Gleitender gewichteter Durchschnitt → angewendet auf Intervallebene.
-
≥ 2 Jahre Daten: Bestes Modell ausgewählt mit MAE → angewendet auf Intervallebene.